

For companies competing against the Big 3 cloud providers, some of the greatest success stories come from bold startups that reimagined the ways data could be stored, structured, and used.
 Listen to this article >
Listen to this article >
In this post, we examine how the data warehouse, lakehouse, and semantic layer could combine to create a platform for data apps and challenge the Big 3 as the cloud central nervous system for companies.
As we discussed last year, one of the largest examples of an individual company succeeding against Big Cloud is Snowflake, which represented a paradigm shift in the maturation of cloud technology when it went public in 2020 and is now a $46B market cap company as of May 17th, 2022.
Snowflake was able to succeed in the shadow of AWS Redshift and Google’s BigQuery not with open source, but by building deep IP combined with operational excellence. By rethinking the entire data warehousing process by separating storage from computing, they were able to exploit the fundamental advantage of cloud computing; turning storage, compute, and networking into an elastic resource to build a better database.
VCs are already looking for “the next Snowflake”, with companies like Clickhouse raising $300m in 2021 and Rockset and Materialize competing to be the streaming Snowflake. To solidify their staying power, the next chapter for Snowflake and other cloud data warehouses is to continue to expand as a platform company and challenge the cloud providers as the dominant cloud platforms for developers.
As we’ve seen in the companies tracked in our Castles in the Cloud project, the cloud data warehouse ecosystem has already exploded, spurring the growth of companies like Fivetran/Airbyte (moving data to CDW), dbt (transforming data within CDW), Looker/Mode (BI), Census/Hightouch (reverse ETL, syncing and operationalizing data out of Snowflake), Monte Carlo/Bigeye (data observability in the CDW), and data access governance players to help customers develop a modern data stack for their analysts.
However, the key to this platform future lies a step beyond the core analytics ecosystem with the rise of data applications. In data apps, the data warehouse functions not just as a company’s static data store from which to analyze data, but as the dynamic brain for applications. Snowflake has a developer page with some examples of both internal and customer-facing apps developers have built, including a reference architecture.
A number of security companies have begun this approach, including Lacework, Hunters, and Panther. Snowflake is incentivized to invest in and promote solutions that drive data consumption to their platform and expand their data footprint. They recently paid $800m to acquire Streamlit, which takes this vision a step further – long-term, Streamlit may represent an effort to develop a Snowflake app store to distribute applications built on top of Snowflake and further increase consumption.
This platform for data apps constitutes a meaningful challenge to a few of the Big 3 cloud providers core capacities. BigQuery is a $1B+ business comparable to Snowflake, while Redshift has more than 15k customers. But beyond the data layer, data apps represent an opportunity to layer on other services and compete against parts of our tracked App Development and Dev Tools markets.
This vision of applications built on top of cloud data platforms is an audacious one, but the story to be written may involve two other key concepts: the lakehouse and the semantic layer.
What is a Lakehouse?
At the core, lakehouses are designed to upgrade data lakes while providing the structure and guarantees of data warehouses across diverse workloads on top of cheap S3 or blob storage.
Uber pioneered the concept in 2017, discussing a version of the architecture in their engineering blog that they open-sourced as Apache Hudi. Databricks coined the lakehouse terminology itself and began evangelizing it in 2020, observing the emergence of the architecture among leading tech companies and their customer base in their engineering blog. Databricks Delta, Onehouse (from the Apache Hudi team), and Tabular (from the Apache Iceberg team) constitute the leaders in the lakehouse market today.
How Do They Work?
Lakehouses improve upon both data lakes and warehouses in several ways. Data lakes – which have been out of vogue for the past decade due to the rise of warehouses – do not enforce data quality or support ACID transactions. They also lack consistency and isolation, making them more difficult to manage – and less suitable for most business analytics use-cases than data warehouses. Companies may still use them as a raw store of data, but they have not progressed to return the type of analytical value that was expected at the onset of the Hadoop wars between Cloudera and Hortonworks.
But lakehouses support ACID transactions, allowing multiple pipelines to read and write at the same time, and add schema enforcement, governance, and auditing mechanisms.These advances are possible because of open table format like Delta, Hudi, or Iceberg that form the core of the lakehouse architecture.
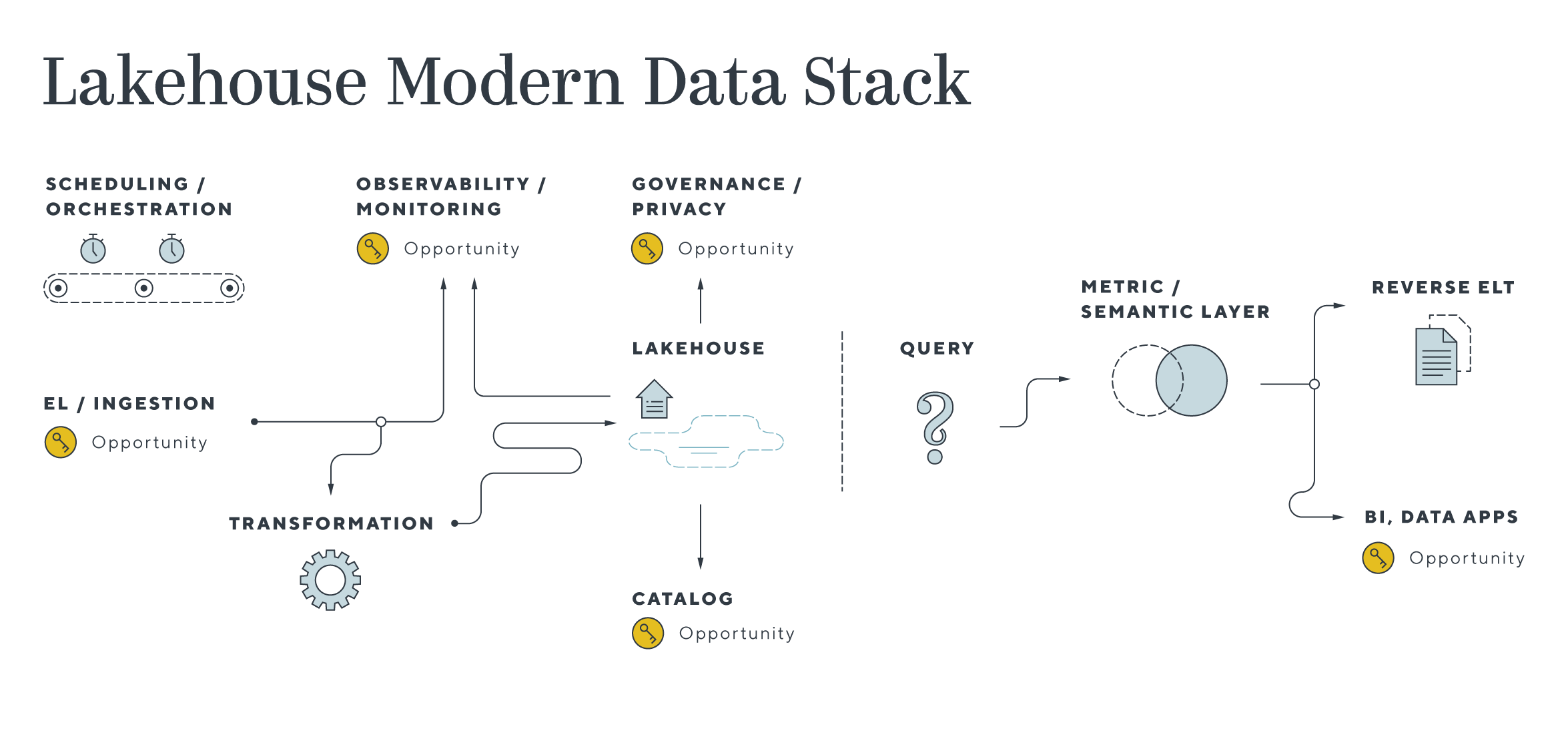
While data warehouses serve SQL analytics use cases well, companies still typically need to maintain separate systems for the real-time streaming, machine learning, and data science use cases that constitute the next wave of the data revolution. A structured data warehouse environment does not handle the unstructured data commonly used for ML/DS, nor are they architecturally suited for the quick incremental updates and materialized views necessary for real-time and streaming analytics.
This architectural gap taxes data teams as they need to maintain multiple systems and incur extra costs as data must be duplicated and moved across systems.
Lakehouse architecture provides several benefits compared to data warehouses:
1. Cost savings – By virtue of residing on cheap storage, lakehouses provide significant cost savings against data warehouses at scale
2. Single platform – Lakehouses enable a combined platform across business analytics, AI/ML/unstructured data workloads, and real-time streaming use cases, simplifying the management of maintaining two separate data platforms.
3. Open ecosystem – Snowflake pioneered the separation of compute and storage at the product level, but the lakehouse architecture enables that at the vendor level. Unbundling the data from the query layer prevents vendor lock-in and allows users to leverage multiple query engines, selecting the optimal engine based on the use case, latency requirements, etc.
Given its advantages, the lakehouse architecture represents a challenge to the cloud data warehouse to become the core of the data platform. Its development also presents an opportunity for the open data ecosystem at large, not only to expand the number of potential workloads for query engines like Presto and Trino but also creating the possibility for a similar ecosystem to the aforementioned cloud data warehouse one.
Whether the core becomes the cloud data warehouse or the lakehouse, the cloud data platform needs at least one additional component to reach this promise – the semantic layer.
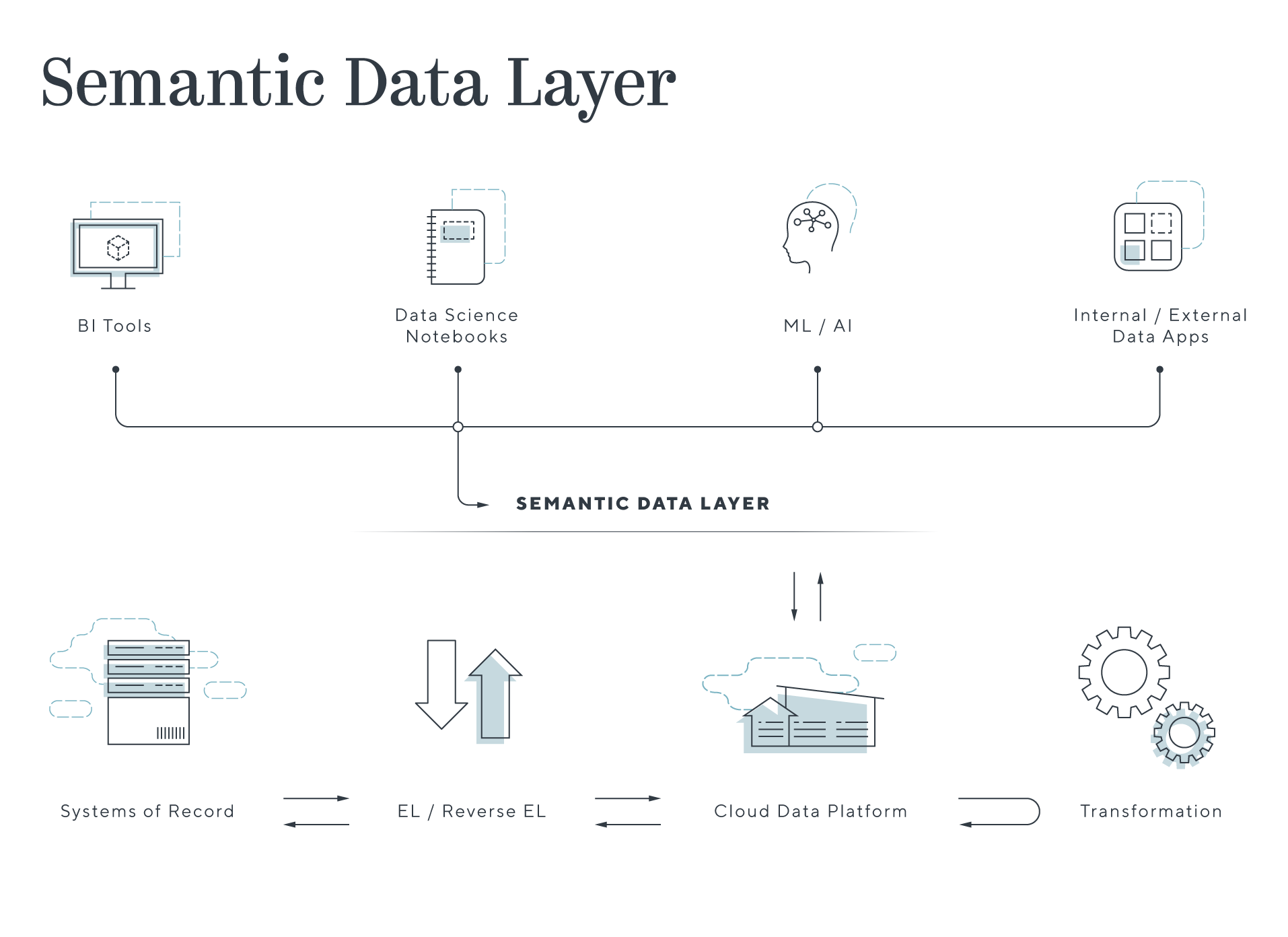
What is a semantic layer?
The semantic layer is an evolution of the metric store and headless BI concepts that have arisen over the past few years. A metric store standardizes metric definitions and business logic in a layer independent from downstream systems like BI, ML notebooks, and applications. This ensures consistency across a company and helps preclude breaks in downstream systems as changes are made in the core data store, creating a headless BI system akin to the headless CMS systems.
The semantic layer generalizes this approach beyond metrics, creating an API for people and applications to access business objects directly. Analysts can engage directly with concepts like customers, plans, and products, and applications can be built upon a much more stable environment than custom queries. Eventually, these applications may be able to write back to the database as well, creating a transactional experience for these data applications. Benn Stancil from Mode discusses the concept in more depth in his excellent blog here.
Combining this more mature development base with simple, scalable, and unified cloud data warehouses or lakehouses can realize the vision of the cloud data platform and challenge the platform dominance of the 3 cloud providers at the cloud developer level.
DBT seems best positioned to create this layer given their amazing developer community and transformation capabilities, and they wrote about the concept as the next layer in the modern data stack in announcing their most recent funding. In discussing their development of the semantic layer, DBT Labs also calls for third-party development within the ecosystem, including observability, dynamic governance, privacy tooling, etc.
DBT’s expansion into the semantic layer also provides a warning about building in ecosystems as product boundaries shift – companies like Transform Data that have been working on developing the leading independent metric stores now face well-funded competition. Of course, independents can still win out over platforms with diluted focus, and DBT’s semantic layer appears to be early in development.
We are excited to see and back startups developing across the Snowflake, Lakehouse, and DBT ecosystems to help create the reality of the cloud data platform.