Arguments for multi-layer decoder-only Transformer #157
Comments
|
Hello, I did some research in language model and transfer learning. This is my 2 cents: We actually can use the regular Transformer architecture to train on language model task.
As you can see input to encoder in this case is the same as input to decoder, because output of previous step is actually the same as input of current time step. Because of this, encoder and decoder are learning from the very same input and can considered redundant learning (I believe it is mentioned in GPT-1 paper that encoder and decoder are probably learning the same thing about language if we use both encoder and decoder). So I think the intuition for decoder-only is to remove model weights those seems learning redundant stuffs, and giving computation capacity to decoder side only so we can have more complex model. This is also interesting that it does not have to be decoder side that we choose to use. Actually BERT model chooses to use encoder side of Transformer instead. They choose to use one side of attention layers for very same reason. The difference is that, BERT paper states that they choose encoder because it is bi-direction attention mechanism - decoder side have mask applied in attention so any token in N position can attend to tokens from 0 to N-1 position only. |
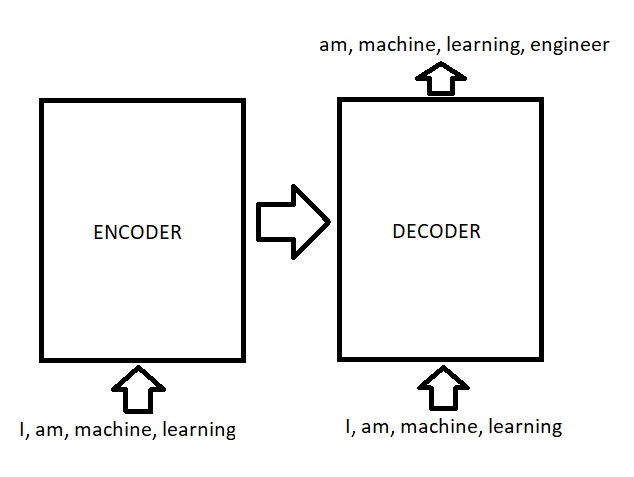
|
In gpt1 paper, they did not mentioned much about the comparison between decoder-only Transformer VS both-encoder-decoder Transformer. But in the original paper (who proposed decoder-only model) "GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES", they briefly mentioned the motivation, as well as experimental results comparing these 2. Motivation quoted from the paper: Experimental results quoted from the paper: However, the above experimental results seems a little bit surprising to me, since T-Decoder gets a much better results than T-ED when L is larger then 1000. I agree encoder might not be able to provide extra value (since the information could already be learned by decoder). But I do not know why T-ED's encoder would hurt the performance when L becomes larger (this can not be explained by "giving computation capacity to decoder side only so we can have more complex model"). |
|
Is it possible that we could use other transformers as encoder(like BERT) and other transformers as decoder(GPT1,GPT2 or XLNet)? |
Thank you for correct me about the comparison between decoder-only Transformer VS both-encoder-decoder Transformer. It is actually in the prior paper "GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES". I remember it incorrectly. Anyway, below is my opinion about T-ED and T-D training efficiency.. Please correct me if I am wrong. I think the training objective of "Next token prediction" with T-ED may be inefficient because the attention of Encoder side, which is not masked so it can attend to every token except the last one.. Let's say that we have 1st -> N-1th tokens as input to both Encoder and Decoder, the model have to predict tokens 2nd -> Nth. Every hidden nodes in Encoder side already "See" 1st -> N-1th input tokens, so the objective task is to actually "Shift all tokens to its left and predict only the Nth token". While in T-D model, each hidden nodes in Decoder can only attend to (or "See") tokens on their left-hand-side, and have to predict the token at its position. So the objective task is much harder than the T-ED counterpart given the same input, and label... because it has to really predict tokens in every position. May be this can be source of higher efficiency in T-D model. |
Hello, I recently started studying language modeling and GPT(-2) in particular. While I start to understand the way it is trained/fine-tuned, I do have some questions about its architecture.
In OpenAI's paper it is stated that GPT (and GPT-2) is a multi-layer decoder-only Transformer. From a higher perspective I can understand that an Encoder/Decoder architecture is useful for sequence 2 sequence applications, but that it becomes less attractive for language modeling tasks. Therefore, it seems logical OpenAI decided to stick with the multi-layer decoder only. However, during the training/fine-tuning stage of GPT, in these decoding-layers, tokens are still encoded and eventually decoded, right?
I'm not sure whether my question is clear, but it basically comes down to this: in GPT's paper it is stated that they use a decoder-only transformer, but I cannot find any arguments this decision is based on. What would be the difference if they stuck to the regular Transformer architecture for example?
I hope someone is able to give me more insight into this.
Many thanks in advance.
The text was updated successfully, but these errors were encountered: